Action Imitation in Common Action Space for Customized Action Image Synthesis
Abstract
We propose a novel method, \textbf{TwinAct}, to tackle the challenge of decoupling actions and actors in order to customize the text-guided diffusion models (TGDMs) for few-shot action image generation. TwinAct addresses the limitations of existing methods that struggle to decouple actions from other semantics (e.g., the actor's appearance) due to the lack of an effective inductive bias with few exemplar images. Our approach introduces a common action space, which is a textual embedding space focused solely on actions, enabling precise customization without actor-related details. Specifically, TwinAct involves three key steps: 1) Building common action space based on a set of representative action phrases; 2) Imitating the customized action within the action space; and 3) Generating highly adaptable customized action images in diverse contexts with an action similarity loss. To comprehensively evaluate TwinAct, we construct a novel benchmark, which provides sample images with various forms of actions. Extensive experiments demonstrate TwinAct's superiority in generating accurate, context-independent customized actions, while maintaining the identity consistency of different subjects, including animals, humans and even customized actors.
Method
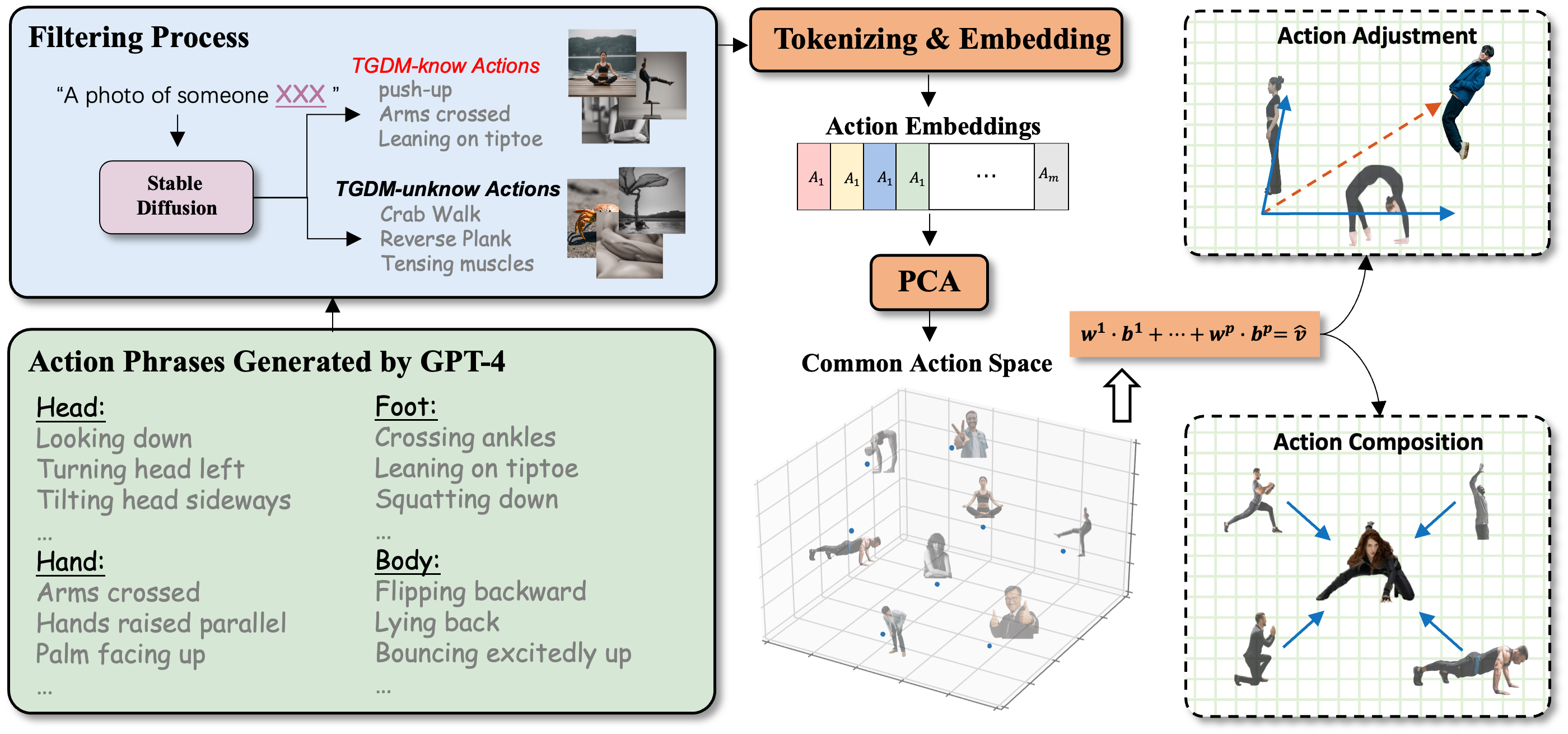 Figure 1. The building process of the Common Action Space. First, we collect about 832 action phrases as the initial collection, visualized on the left. Each action phrase is tokenized and encoded into an action embedding group. Then we conduct a Principle Component Analysis to build a compact orthogonal basis, visualized in the middle. With the action space, we can adjust the action or combine some actions to generate new actions, visualized in the right.
Figure 1. The building process of the Common Action Space. First, we collect about 832 action phrases as the initial collection, visualized on the left. Each action phrase is tokenized and encoded into an action embedding group. Then we conduct a Principle Component Analysis to build a compact orthogonal basis, visualized in the middle. With the action space, we can adjust the action or combine some actions to generate new actions, visualized in the right.
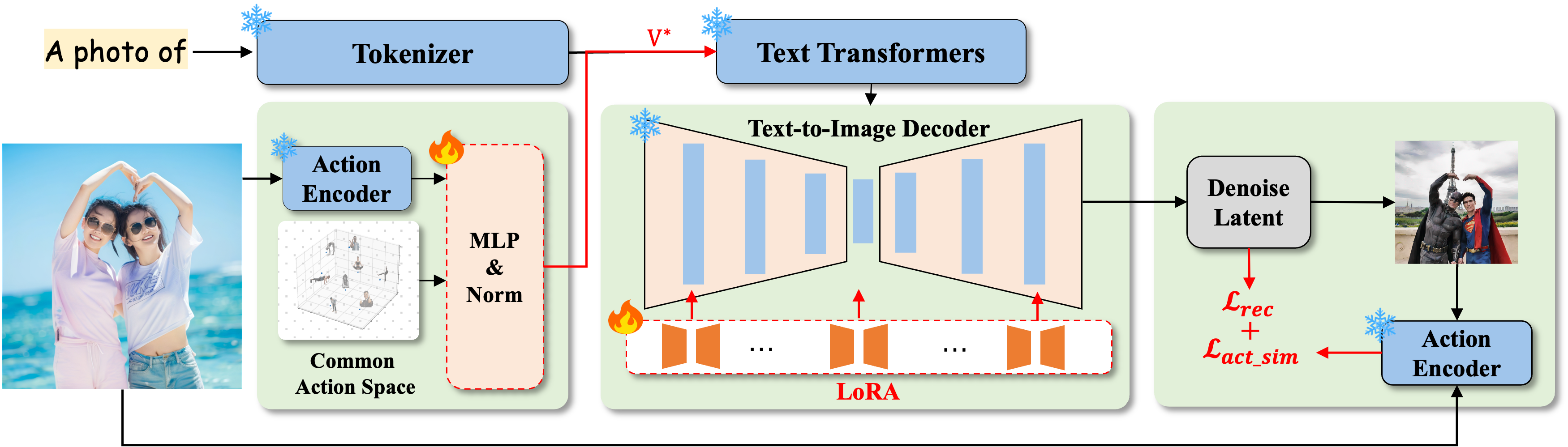 Figure 2. The overview of the proposed TwinAct. We optimize the coefficients of the action bases to avoid encoding the action-irrelevant features. After training, we combine the learned coefficients and shared action base to generate images with the customized action.
Figure 2. The overview of the proposed TwinAct. We optimize the coefficients of the action bases to avoid encoding the action-irrelevant features. After training, we combine the learned coefficients and shared action base to generate images with the customized action.
Qualitative Results
 Figure 3. Compare TwinAct with other methods. TwinAct preserves the identity consistency of actors while allowing customized actions to be accurately generalized across different actors by effectively decoupling actions and actors.
Figure 3. Compare TwinAct with other methods. TwinAct preserves the identity consistency of actors while allowing customized actions to be accurately generalized across different actors by effectively decoupling actions and actors.
 Figure 4. The results of customized action generation with TwinAct.
Figure 4. The results of customized action generation with TwinAct.
 Figure 5. The results of customized actors performing customized actions generated by TwinAct
Figure 5. The results of customized actors performing customized actions generated by TwinAct